
While testing and developing modern apps, you’d encounter certain scenarios where you need to extract specific data from the website. The current market offers various ways to perform this process. XPath is the crown bearer in this segment due to its power and flexibility.
You need to be aware of the full syntax and strategies of XPath to utilize its full potential for this process. However, we have covered you if you’re new to this segment. Our blog will explore advanced XPath strategies to make web scraping efforts more efficient and robust.
Understanding XPath
Before diving into the complexities, let us address the elephant in the room: What is XPath? It is a query language to select nodes from an XML document. You can use it mainly in web scraping to navigate XML and HTML elements. To perform this process, XML uses the principle of path expressions to select nodes or node sets.
An interesting fact is that these path expressions are highly similar to the path expressions that we use in traditional computer file systems. The syntax of XPath can be mainly classified into the following two categories:
The absolute path approach selects an element that is a direct child of the preceding element.
On the other hand, the relative path selects all elements in the document regardless of their position within the document tree.
XPath also uses predicates to find a specific node. Using this process, the testers can also find nodes containing a specific value they require during the test execution process. Let us now divert our attention towards the two forms of predicate implementation within the XPath syntax:
- ‘//div[@id=’main’]’ will select all ‘div’ elements with an ‘id’ attribute of ‘main.’
- ‘//div[@class=’header’][1]’ will select the first ‘div’ element with a ‘class’ attribute of ‘header.’
Advanced XPath Technologies
Let us now take a detailed look at some of the most advanced XPath technologies that the testers and developers must implement within the web scraping process:
Using Axes
Axis are often considered the backbone of an XPath syntax. This is because you will use these elements to navigate through the HTML structure and other attributes in an XML document. Axes also help the testers to define the node set relative to the current node.
To improve our knowledge about the implementation of these methods, let us go through some of the most commonly used Axes within the XPath infrastructure:
- The child Axe will allow you to select all the children nodes within the current node.
- On the other hand, the parent node selects the parent of the current node within the document structure tree.
- You can use the sibling Axe to select the following or preceding siblings present within the current node we’re working on.
- The ancestor Axe will select all ancestors, including the parents and grandparents of the current node within the XML or HTML structure.
- Finally, the descendant node will select all descendants, like children or grandchildren of the current node, present within the website structure.
To further help you understand the implementation of access and their functioning pattern, we have mentioned a sample code snippet that implements it within the terminal window:
//div[@id=’main’]/descendant::a – Selects all `a` elements that are descendants of the `div` element with an `id` of `main.`
Using Functions
XPath will provide a native and rich set of functions that you can use to manipulate number strings and node sets.
Within the string functions, you will have the “contains()” and the “starts-with()” functions. The “contains()” function will select all the ‘div’ elements whose class attribute contains the mentioned string ‘header.’ On the other hand, the “starts-with()” function will select all elements whose ‘href’ attribute starts with the mentioned data.
With XPath, you will also have a separate series of functions known as the position functions. It consists of ‘position()’ and ‘last()’. The ‘position()’ function will select all the first ‘div’ elements. On the other hand, as the name suggests, the ‘last()’ function will select the last ‘div’ element.
Let us now understand the functioning of XPath string and position functions by analyzing a code snippet that you can easily enter in the terminal window:
//a[contains(text(), ‘Read More’)]
Combining Multiple Functions
Another advanced and interesting process of XPath is that it allows you to combine multiple functions using logical operators. This means that you can use operators such as ‘and’ and ‘or’ to combine various string functions, position functions, or axes as per the requirement of your application development and testing project.
To further understand the concept of combining multiple functions, we have mentioned a sample code snippet that will allow you to further grasp this idea:
//div[@class=’content’ and @id=’main’] – Selects all `div` elements with both `class` attribute `content` and `id` attribute `main`
Handling Dynamic Content
It can be a challenging process to perform web scraping on web pages that consist of dynamic data. These data can massively change their positioning or functioning depending on parameters such as user interactions, device specifications, or device orientations. In most of the cases, these functions are generated by JavaScript elements.
In such cases, you can use tools like Selenium to render the JavaScript content before extracting the data. Selenium will also allow you to integrate automation testing to automate the testing and web scraping process and further streamline the delivery operations.
We will learn more about the scope of automation testing with XPath in the later part of this article. The following code snippet will allow you to implement a dynamic element-handling process with Selenium:
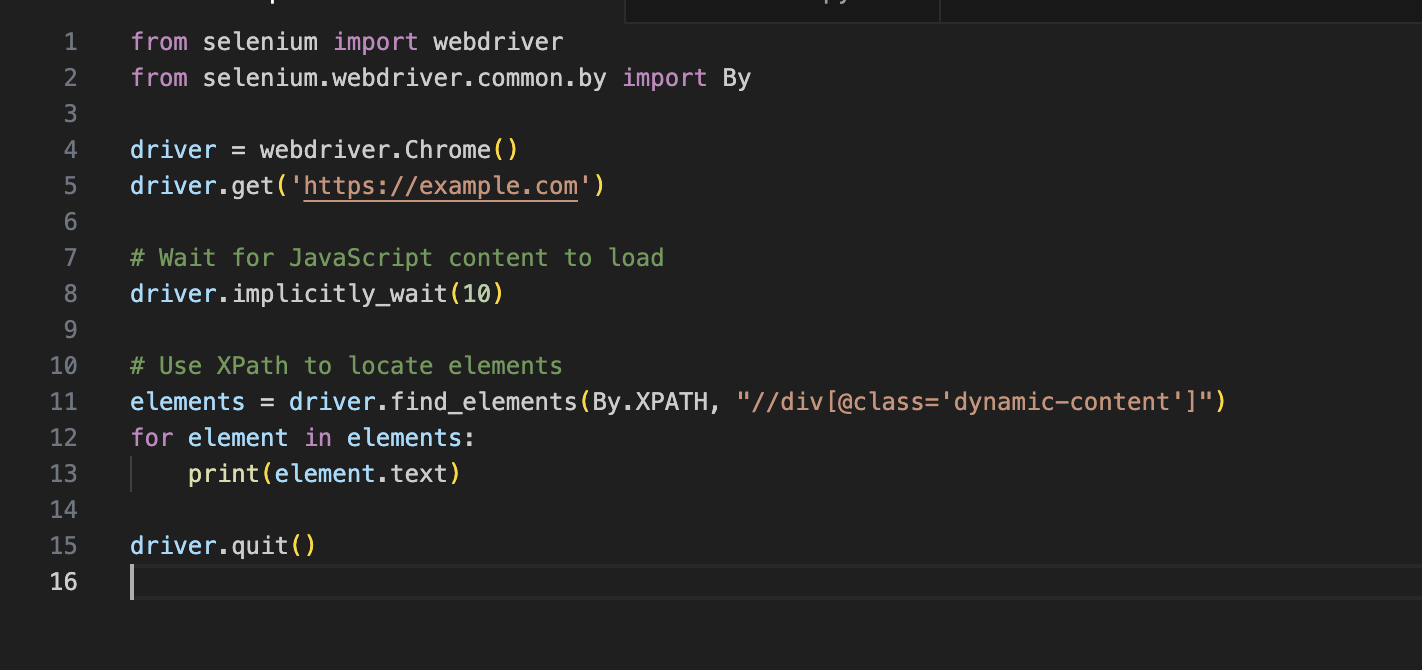
Using Regular Expressions
The XPath version 2 update has introduced support for regular expressions. The testers can implement these expressions with XPath using the ‘matches()’ function. However, remember that this implementation is unavailable on all XPath functions. Despite this, it can be a very powerful tool for complex pattern matching if you can grasp the core concept of it.
To further help with the understanding of regular expressions, we have mentioned a sample code snippet that allows the implementation of this process in the terminal window:
//a[matches(@href, ‘^https?://’)] – Selects all `a` elements with an `href` attribute starting with `http` or `https`
Using Namespaces
It is common to come across various XML documents that use namespaces. In such cases, you must include the namespace within the XPath query. The following code snippet helps further understand the implementation of this process:
//*[local-name()=’div’ and namespace-uri()=’http://www.w3.org/1999/xhtml’] – Selects all `div` elements in the XHTML namespace.
Integration With Automation Testing
Since XPath is the most commonly used method for locating website elements, you can integrate it with your automation test scenario to further streamline the testing and development process.
Cloud platforms like LambdaTest allow you to integrate XPath with automation testing frameworks like Selenium. LambdaTest is an AI-powered test orchestration and execution platform that lets you perform manual and automated testing at scale with over 3000 real devices, browsers, and OS combinations.
To further shed more light on this segment, we have mentioned a sample code snippet that allows the developers to perform this test scenario:
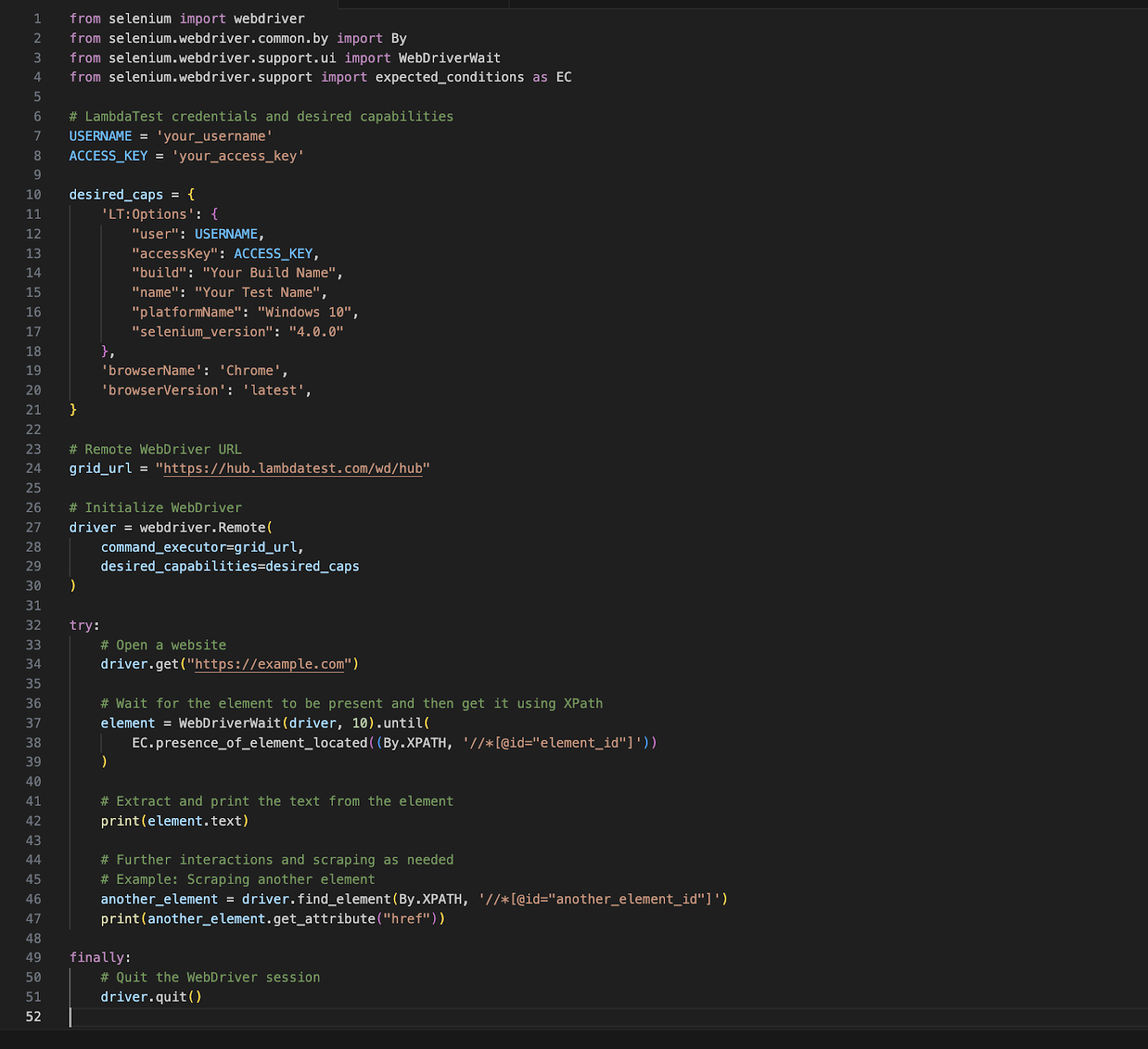
Optimizing XPath Queries
We strongly advise the testers to invest quality time optimizing the XPath queries to ensure the desired results. To help you with the understanding of this process, we have mentioned some of the most effective strategies in this regard:
- Avoid Absolute Paths
While using absolute paths, you will realize that they can break very easily whenever changes are made to the HTML structure of your website. So, it can massively hamper the core functioning of the application and can completely crash it in a worst-case scenario.
To avoid this issue, we advise the testers to use relative paths that make the XPath queries more robust and scalable. Relative queries can also adapt themselves per the website’s changing structure and requirements.
Use Specific Attributes
Modern apps consist of multiple elements that have a crucial role in the core functioning of the application infrastructure. However, while performing testing actions on these applications, you must use specific attributes to pinpoint your desired element during the web scraping process.
Specific attributes like ‘class’ and ‘ID’ will help narrow the search and make the XPath queries more efficient. This process will also help you reduce the overall time you invest in the search process.
- Reduce The Use Of Wildcards
It is true that the use of wildcards like ‘*’ can be useful depending on your testing or web scraping requirements. However, you should also remember that these wildcards often reduce the efficiency of XPath expressions. So we would highly advise the testers to be specific and use wildcards only if necessary.
- Test The XPath Queries
Before implementing the XPath queries within the scraping process, we advise the testers to test the functioning of these queries and ensure that they do not negatively harm the core application infrastructure.
To perform the testing process, you can use the native browser developer tools or other online XPath testers that are easily available in the present market. Moreover, these tools will provide you with various suggestions that can help you refine the functioning of the XPath queries.
- Properly Handle Exceptions
Modern websites use dynamic web pages that change their behavior, positioning, and functioning based on user interactions or the specific device type. So, while working with these dynamic web pages, the elements might not always be present within the website visuals.
To tackle such a scenario and avoid the possibility of a flaky test result, the developers must handle these elements and test scenarios gracefully. To shed more light on this process, we have mentioned a sample Python code snippet that helps you handle element exceptions:
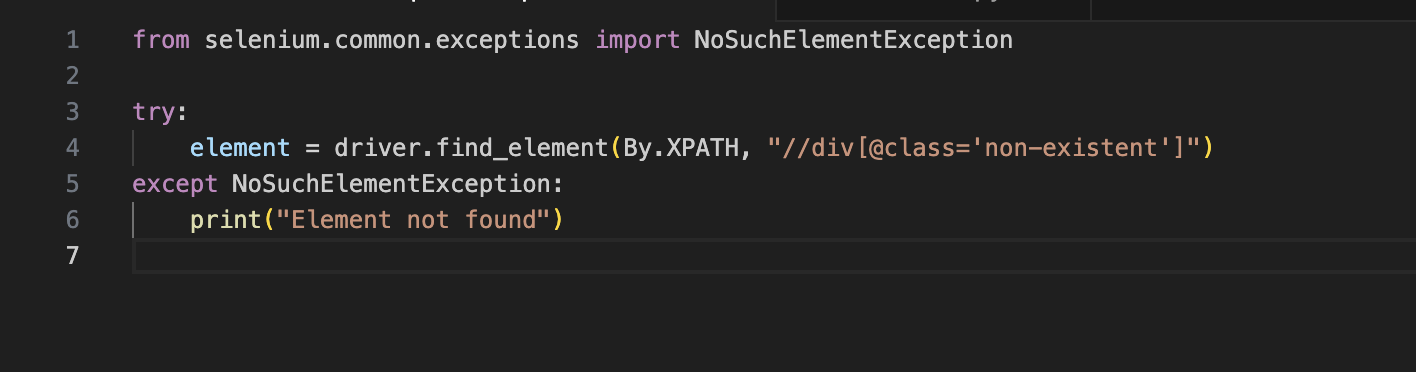
The Bottom Line
Considering all the techniques and strategies discussed in this article, we may safely conclude that XPath is essential for robust web scraping implementation. So, by understanding and applying all the techniques we discussed in this article, you can extract data more efficiently and accurately from complex and dynamic web pages.
Whether dealing with nested data, combining multiple conditions, or working with complex dynamic content, mastering XPath will massively help you improve your web scraping capabilities.
Finally, we can conclude that web scraping is a powerful tool, but it is also important to use it responsibly. Improper implementation of XPath-based web scraping can hurt the performance of the website.